





À l’occasion d’EGC26 à Anglet, plusieurs enseignants-chercheurs et doctorants du De Vinci Research Center (DVRC) ont présenté des travaux en traitement automatique du langage naturel, en indexation documentaire et en vision par ordinateur. Ces contributions portent sur la génération de user stories, la prédiction de mots-clés inter-domaine et le suivi multi-objets multi-caméras.
La participation à la conférence EGC (Extraction et Gestion des Connaissances) prolonge les recherches menées au sein du DVRC, laboratoire commun aux écoles du Pôle Léonard de Vinci. Elle renforce le lien entre production scientifique et formations du cycle ingénieur et des MSc en Data et Intelligence Artificielle.
L’Association EGC : fédérer la communauté francophone en science des données
L’Association Internationale Francophone d’Extraction et de Gestion des Connaissances (EGC) rassemble les chercheurs en science des données et des connaissances au sein de l’espace francophone.
Son objectif consiste à promouvoir les échanges multidisciplinaires entre apprentissage automatique, statistiques et analyse de données, systèmes d’information, bases de données et de connaissances, web sémantique ou web des données.
Ces échanges se développent également en lien avec les spécialistes d’entreprise qui déploient des méthodes et outils adaptés à leurs besoins opérationnels.
L’association constitue ainsi un cadre structurant pour présenter l’état de l’art, identifier les enjeux scientifiques et applicatifs, et accompagner le développement de cette communauté autour de l’exploitation des gisements de données et de connaissance.
Nicolas Travers, Full Professor (HDR) et Deputy Director du DVRC, Marius Ortega (promo 2024), doctorant Onepoint & DVRC, Saber Zahhar (promo 2022), doctorant DVRC, Nedra Mellouli-Nauwynck, responsable de la majeure Data et Intelligence Artificielle, Christophe Rodrigues, enseignant-chercheur, Pierre Lefebvre, doctorant au DVRC, et Ahmed Azough, Full Professor, PhD-HDR, Head of Computer Science & Data Science MSc, ont présenté trois contributions scientifiques.
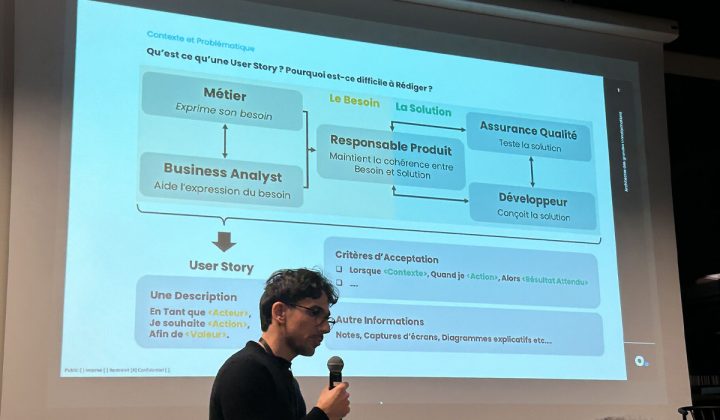
La presentation de Text2Stories : Extraction et Génération de User Stories à partir de Documentation Fonctionnelle et Non-Fonctionnelle
Text2Stories : génération et évaluation automatisée de user stories
Les user stories occupent une place centrale en ingénierie logicielle, en particulier dans les méthodes Agiles. Elles formalisent les exigences fonctionnelles et non-fonctionnelles du point de vue utilisateur. Leur exploitation en traitement automatique du langage naturel reste limitée par le manque de jeux de données publics combinant qualité rédactionnelle, métriques établies et contexte projet.
Le projet Text2Stories propose un outil d’intelligence artificielle multi-agents capable de générer et d’évaluer des user stories contextualisées à partir de documentations fonctionnelles et non-fonctionnelles. L’objectif consiste à produire des résultats comparables et reproductibles, tant pour la recherche que pour les pratiques professionnelles.
L’approche répond aux contraintes des environnements open source et distribués, où les interactions synchrones sont réduites. Elle vise à structurer l’évaluation des user stories au-delà des révisions orales informelles, telles que la cérémonie des « Trois Amigos », et à soutenir l’automatisation des processus qualité.
Prédiction de mots-clés inter-domaine : une alternative aux modèles génératifs
La génération automatique de mots-clés demeure dominée par des architectures encodeur-décodeur de type seq2seq. Ces modèles présentent des limites en termes de généralisation hors domaine, de latence et de consommation de ressources.
Les travaux présentés proposent une architecture uniquement basée sur l’encodage, dédiée au classement de mots-clés issus d’un regroupement inter-domaines. Chaque document est traité comme une requête : les mots-clés des documents voisins sont collectés, puis classés à l’aide d’un modèle Sentence-Transformers ajusté par fine-tuning.
L’apprentissage repose sur un objectif contrastif de type multiple negatives ranking. Une adaptation spécifique permet de prendre en compte les recouvrements sémantiques entre documents, afin d’éviter de pénaliser des mots-clés pertinents partagés par plusieurs corpus.
Les expérimentations comparent cette approche à des bases seq2seq selon différents critères : f-score, rappel pour mots-clés présents et absents, robustesse hors domaine, latence, coûts d’entraînement et d’inférence, empreinte environnementale. Les résultats indiquent des performances équivalentes ou supérieures aux modèles génératifs, avec une réduction des contraintes computationnelles.
Neo4MOT : suivi multi-objets dans un réseau de caméras
Le suivi multi-objets multi-caméras (MCMOT) constitue un enjeu en vision par ordinateur, notamment pour l’analyse de scènes complexes comportant des occlusions.
La méthode Neo4MOT repose sur un modèle de graphe temporel multicouche structurant les trajectoires d’objets. Elle combine un réseau de neurones convolutionnel (CNN) pour l’extraction de caractéristiques visuelles et un algorithme de graphe pour l’agrégation et l’association des trajectoires observées depuis différentes caméras.
Les démonstrations s’appuient sur les jeux de données CAMPUS, EPFL et PETS09. Plusieurs algorithmes de suivi, dont SORT, OC-SORT et ByteTrack, sont comparés. La visualisation des trajectoires est réalisée avec Neo4j, offrant une représentation graphique des interactions et des déplacements dans le temps.
Recherche et formation en Data et Intelligence Artificielle
Ces travaux reflètent les axes de recherche développés au DVRC en traitement automatique du langage, en data science et en vision par ordinateur. Ils alimentent également les enseignements de la majeure Data et Intelligence Artificielle du cursus ingénieur ainsi que du MSc Computer Science & Data Science.
La participation à EGC contribue à renforcer les passerelles entre recherche, innovation technologique et formation des futurs ingénieurs et experts en science des données.
En savoir plus sur la majeure Data et Intelligence Artificielle et le MSc Computer Science & Data Science de l’ESILV.












